 Так получилось, что нагрузка на VDS выросла. Django кушает ресурсов достаточно хорошо. И я переехал на новый. Памяти в нем оказалось 8Гб, что позволило хорошо развернуться. Для разгрузки я раньше использовал memcached и самую распространенную библиотеку для него — pylibmc — типовая связка, которая описывается везде. Но как-то для кэширования разовых запросов производительность его по сравнению с кэшем mariaDB меня не устраивала. Запрос из кэша БД выполнялся 0.1-0.5мс (десяток записей), а из мемкэша 0.7-1. Это я замерил полноценно, подключив New Relic — замечательное средство мониторинга, но стоит достаточно дорого. Правда есть триальные 2 недели, которыми я и воспользовался.
Так получилось, что нагрузка на VDS выросла. Django кушает ресурсов достаточно хорошо. И я переехал на новый. Памяти в нем оказалось 8Гб, что позволило хорошо развернуться. Для разгрузки я раньше использовал memcached и самую распространенную библиотеку для него — pylibmc — типовая связка, которая описывается везде. Но как-то для кэширования разовых запросов производительность его по сравнению с кэшем mariaDB меня не устраивала. Запрос из кэша БД выполнялся 0.1-0.5мс (десяток записей), а из мемкэша 0.7-1. Это я замерил полноценно, подключив New Relic — замечательное средство мониторинга, но стоит достаточно дорого. Правда есть триальные 2 недели, которыми я и воспользовался.
Итак. по теме:
Я конечно понимал, что проблема медлительности мемкеша в необходимости постоянных соединений. И решил поискать модуль с пулом. Он нашелся довольно быстро — django-memcached-pool. И базируется он на umemcache. Вот так все просто оказалось. Самое удивительное, что на русском языке я информации не нашел. Замена модулей дала ускорение memcached до 0.05-0.2мс на тех же данных, что вполне хорошо. Хотя может все это прирост umemcache, так как все на одном сервере.
Подключается все как обычно:
pip install django-memcached-pool
А в конфигурации джанго-проекта нужно указать:
CACHES = {
'default': {
'BACKEND': 'memcachepool.cache.UMemcacheCache',
'LOCATION': '127.0.0.1:11211',
'OPTIONS': {
'MAX_POOL_SIZE': 100,
'BLACKLIST_TIME': 20,
'SOCKET_TIMEOUT': 5,
'MAX_ITEM_SIZE': 1000*100,
}
}
}
Когда все устаканилось, я посмотрел на графики. Memcache уже не так выигрывал mysql. Разница в основном за счет запросов с JOINами и некешированных у последнего. На pylibmc среднее было 0.7мс. Пик ближе к концу — это Cron-задание, нагружающее процессор на максимум. Да и БД подгружает тоже. В итоге использую memcache для разгрузки БД, так как ее время доступа зависит от большего количества факторов. После кэширования части данных, провалов Apdex (процент запросов, укладывающихся в лимит) стало намного меньше.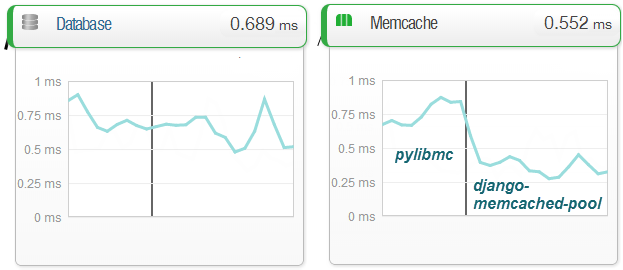
Все же основания нагрузка в django на БД и шаблонизатор. Значит, самое основное действие — увеличение количества ядер. Можно конечно заменить шаблонизатор на jinja, но не особо хочется этого делать. И переписать основные запросы без использования ORM. Если будет не лень, проверю прирост.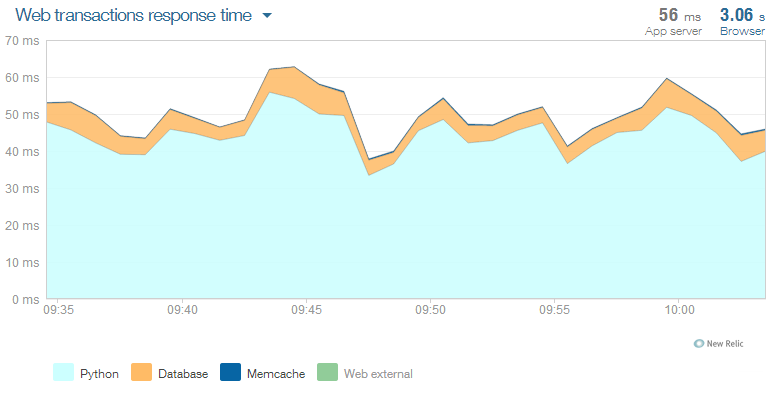
К слову, пробовал levelDB. Синтетический тест показал почти 100к записей и 350к чтений в секунду. Правда она файловая и не многопоточная. Но для одной задачи, где нужно хранить и обновлять много миллионов записей, а затем получать по ним сводку, вполне подошла. ОЗУ для этой цели не подходит, так как первичное заполнение очень долгое. Пробовал Redis, опять же, почему-то у меня он оказался медленнее mysql. Memcache не подходит в силу того, что это кэш. С тарантулом опять какие-то проблемы с адаптером для питона. Разбираться не стал, отложил до лучших времен. Другие Key-Value пока не пробовал.